
NUMA NUMA - Architectural Overview
Architectural overview of NUMA
No not the silly youtube video, Non-Uniform Memory Access (NUMA) is a design model used in many newer multi-cpu computer systems. To understand NUMA it is best to first understand how things were before the its advent. The prototypical multiprocessor computer layout is symmetric multiprocessing (SMP) which uses a uniform memory access (UMA) model. The UMA nature of SMP means that each cpu is connected to a single memory bus. This methodology works well for a relatively small number of CPUs but as the number grows the contention for a single bus grows and cpus start having to wait in line for memory access for unacceptable lengths of time.
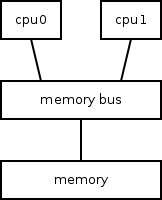
Bellow is a simple diagram of a SMP setup with 2 cpus connected to a single memory bus which is in turn connected to a single bank of memory.
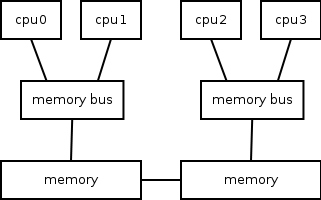
Next is a diagram of a NUMA setup with 4 cpus and 2 memory buses 2 cpus each. The 2 memory buses have their own bank of memory which in the NUMA nomenclature is referred to as local memory. The memory connected to the other bus is accessible however since it is not directly connected there are performance reductions for fetching information from a “remote” memory bank. This concept of local and remote memory is the fundamental principle of the NUMA architecture. Another important term when talking about NUMA is a node; in the diagram each group of memory and cpus that are connected to the same bus are considered a node.
The main consideration that needs to be make when building a NUMA aware system is recognizing the fact that not all memory takes the same amount of time to access. Memory allocations and process cpu locality need to be done taking account for what node the process that is requesting the allocation is in, and when doing process scheduling attempting not to evict a process from a cpu in one node to a cpu in a different node is important to providing the best performance.
Since cpus in addition to the main memory also include their own on chip caches another complication surfaces keeping all the caches consistent. This issue is referred to as cache coherence and affect all multi-cpu configurations that have a shared memory resource. Virtually all NUMA setups you will see in the wild are Cache coherent NUMA (ccNUMA) and I am not going to talk about non coherent setups.
Yet another complication with NUMA comes from the fact that accessing remote memory takes longer which can lead to problems with locking mechanisms. Taking the above diagram as an example if there is a lock structure in memory local to CPU0/1 a situation where the remote cpus are unable to take hold of the lock can occur. Say cpu0 is holding a spinlock, cpu2 then requests the lock and starts spinning, then cpu1 requests the lock and spins. Once cpu0 releases the lock due to the delay in accessing remote memory cpu2s request will likely have been beat out by cpu1.
Overall NUMA allows an operating system that is correctly accounting for the quirks of the design to scale well beyond the limitations of SMP. This mostly is due to the reduction of contention of a single memory bus which reduced the performance gained on SMP systems for each cpu added. The way most of us will see NUMA implemented is on dual or quad socket server motherboards with multi-core cpus. These setups often have a bank of memory for each socket meaning between 2-6 cpus per node.
This concludes the architectural overview. A future article will cover how linux takes advantage of NUMA hardware.